
Rampage Blogs
Web Scraping with Selenium in Python

Owen Crisp
Introduction to Selenium
This is a step-by-step guide on how to get started web scraping in Python using the popular browser automation tool Selenium.
Selenium is a tool for automating website interactions. It’s useful when you need to interact with a browser to perform tasks such as clicking on buttons, scrolling, and navigating through pages. Selenium is also popularly used in web scraping, where it grabs HTML elements and their contents.
As great as Selenium is, it won’t be able to pass complex anti-bot and browser solutions. To help automate unscathed, you’ll need to employ more sophisticated anti-bot solutions and proxies. In this guide, we’ll use Python 3.xx and Google Chrome, the most popular browser for automation. By combining it with other web scraping technologies (such as the popular “Beautiful Soup”), you’ve got a pretty powerful toolset to begin web scraping.
Installing Selenium with Python
Assuming you already have both Python setup and Chrome, you’ll need to install the package in Python. If you don’t have Python installed already, you can download it free here, available on macOS, Windows, or Linux.
Use using the following pip command in your terminal:
pip install selenium
This installs the Selenium package in Python.
We’d also recommend installing the following packages:
pip install webdriver-manager
pip install requests
pip install beautifulsoup4
If you’re unsure whether you have the packages installed already, you can check through the terminal. Open up your terminal, and type the following command:
pip freeze
This will list all installed packages along with their version numbers.
Browsing with Selenium
Selenium is a versatile integration and can be used in the most simple of scripts. First, we’ll practise using Selenium to open a web page. Here’s a basic script to open a website, a completely fictional site full of quotes from famous people:

The first script will simply open the website, and leave you at the homepage. The addition of the input allows you to then close the browser window by hitting return in the terminal you launched the script from, this will close the window.
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://quotes.toscrape.com/")
input("Press return to close the browser...")
driver.quit()
Understanding a Site
You’ll need a target site to scrape and to understand what you need to scrape from that site. For our example, we’re still using the completely fictional site full of quotes from famous people https://quotes.toscrape.com/. We’ll use this site as it's static and laid out in a basic and understandable way, allowing us to break down the specific elements of the site.
Once you’ve decided on the target site, you’ll need to look at what you want to take from the site. To do this, we can identify specific elements of the site to target using the developer tools. You’ll use the developer tools to identity specific class elements from the HTML code of the website:
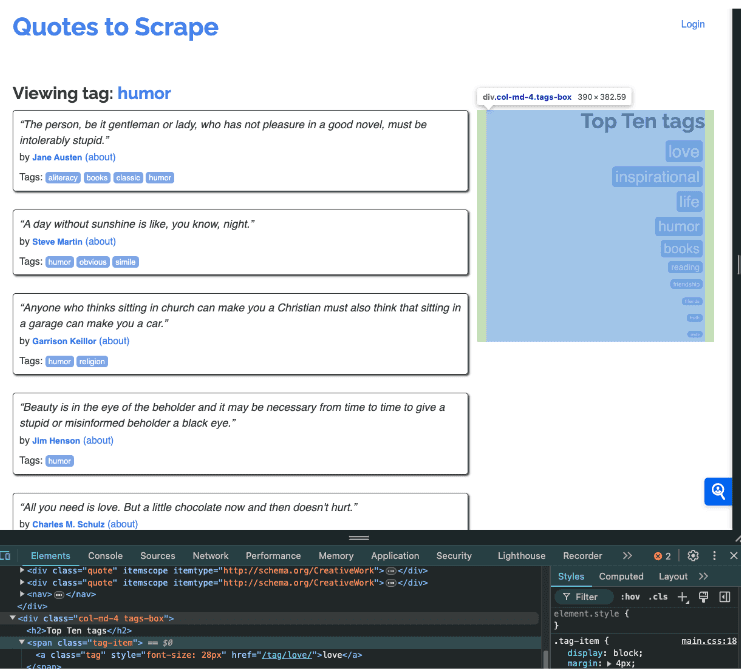
Here we’ve identified the container for the “top 10 tags” by hovering over the source and seeing it highlighted on the page. This can be a good way to identify the elements you want to scrape.
We can build a quick Python script using Selenium to get the source code from the website. By printing the code out right, it might make things easier for you to understand and find the elements you’re looking to scrape. Here we’ve broken the script down into 3 pieces:
Importing:
We’ll import the required libraries for us to be able to scrape the site. The site we are using is very basic, static, and has no difficult antibot to navigate, meaning we just need to import the basic packages.
python
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
Initialising:
This part of the code runs chrome in headless mode. Headless mode runs the browser without a GUI, meaning it’s quicker and less resource intensive. This is common practice for automations, especially in Selenium.
options = Options()
options.add_argument("--headless=new")
driver = webdriver.Chrome(ChromeDriverManager().install(), options=options)
GETting the site:
The final part of the script navigates directly to the specific page to perform a GET request to pull the HTML source code, which is then printed. Finally, terminating the script with the “driver.quit” function.
driver.get("https://quotes.toscrape.com/") print(driver.page_source) driver.quit()
This then prints the entire source code of the website for you to easily scroll through. Unlike earlier, we’ve ran this headless- so you don’t even see the web page open. Once we’ve got this, we can see easier now the point of reference for where we want to scrape:
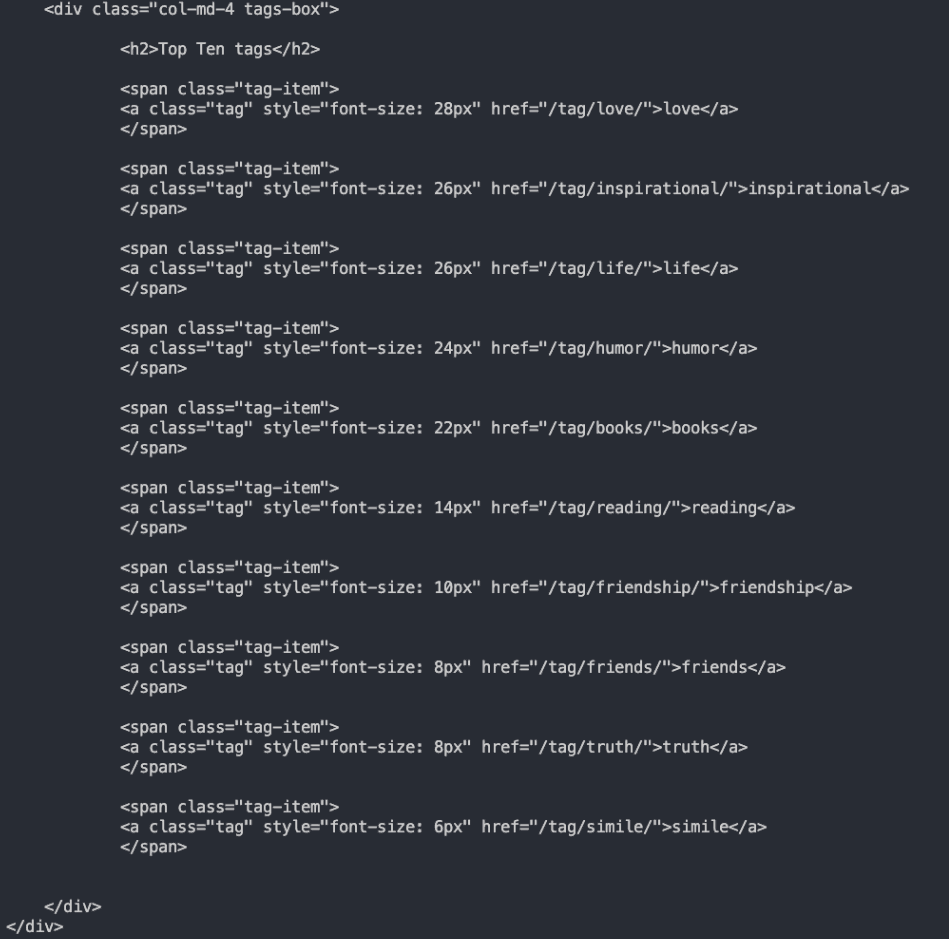
Here's a screenshot of the source code of the website. Specifically, this is the source code for the tags section identified earlier.
Scraping Basics
Now, we’ll show you how to scrape the tags identified. To do this, we’ll use a combination of Selenium and BeautifulSoup. Integrating BeautifulSoup with Selenium allows you to combine Selenium's ability to interact and automate with BeautifulSoup's HTML parsing capabilities. This can be very useful for more complex scraping operations where you need more control over the HTML structure.
# Import the necessary libraries from selenium import webdriver from selenium.webdriver.chrome.service import Service from webdriver_manager.chrome import ChromeDriverManager from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.by import By from bs4 import BeautifulSoup # Set Chrome options to run in headless mode options = Options() options.add_argument("--headless=new") # Start Chrome driver driver = webdriver.Chrome( service=Service(ChromeDriverManager().install()), options=options ) # Navigate to the target website driver.get("https://quotes.toscrape.com/") # Get the page source and parse it with BeautifulSoup soup = BeautifulSoup(driver.page_source, 'html.parser') # Use BeautifulSoup to find the tags to scrape tags_elements = soup.select("div.tags-box a.tag") tags = [tag.text for tag in tags_elements] # Print the tags print("Top 10 tags:", tags) # Close the browser driver.quit()
Successfully ran, you should see the output of:
Top 10 tags: ['love', 'inspirational', 'life', 'humor', 'books', 'reading', 'friendship', 'friends', 'truth', 'simile']
This is great, but what if you wanted to scrape something a little more complex? What if you wanted to scrape the inspirational quotes? If you aren’t feeling motivated now, you will be after this.
If you aren’t familiar with the code, the use of the hashtag “#” lets us comment and annotate the code without it being interpreted or ran. Use these comments as a guide for what the code is doing.
# Import libraries from selenium import webdriver from selenium.webdriver.chrome.service import Service from webdriver_manager.chrome import ChromeDriverManager from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from bs4 import BeautifulSoup import time # Set Chrome options (this runs headded) options = Options() # Uncomment this to to run headless # options.add_argument("--headless=new") # Start Chrome driver driver = webdriver.Chrome( service=Service(ChromeDriverManager().install()), options=options ) # Go to the site driver.get("https://quotes.toscrape.com/") # Sit on the page for a specific time time.sleep(10) # Wait a set time before clicking the link try: inspirational_tag = WebDriverWait(driver, 10).until( EC.element_to_be_clickable((By.LINK_TEXT, "inspirational")) ) inspirational_tag.click() # Wait for the page to load completely time.sleep(5) # Get page source and parse with BeautifulSoup page_source = driver.page_source soup = BeautifulSoup(page_source, 'html.parser') # Scrape "inspirational" quotes and their authors quotes_divs = soup.find_all('div', class_='quote') for quote_div in quotes_divs: quote_text = quote_div.find('span', class_='text').get_text(strip=True) author_name = quote_div.find('small', class_='author').get_text(strip=True) print(f"Quote: {quote_text}") print(f"Author: {author_name}") print("-----") # Press enter to close the browser print("Press Enter to close the browser...") input() # Wait for the user to press Enter finally: # Close the browser when done driver.quit()
There are some key differences between this script and the last. Most notably, this script runs headed. This means you’ll see Selenium physically open a chrome browser, navigate to the page, and then wait- before clicking onto the “inspirational” tag to navigate beyond the home page. Once there, the script gets to work scraping all the quotes with their respective authors.
Using BeautifulSoup, we’ve successfully scraped and parsed the information we wanted, in this block of code:
quotes_divs = soup.find_all('div', class_='quote') for quote_div in quotes_divs: quote_text = quote_div.find('span', class_='text').get_text(strip=True) author_name = quote_div.find('small', class_='author').get_text(strip=True) print(f"Quote: {quote_text}") print(f"Author: {author_name}") print("-----")
Referring to the HTML source code we pulled earlier, we were able to identify that the quotes sit in their own divs of “quotes”. We’re creating our own variable “quote_div” then using BeautifulSoup, iterating through and finding divs with the class of “quote”. A similar process is repeated to get the text, creating another variable of “quote_text” and repeating this process inside the first variable of “quote_div”, identifying all the text by finding the class of “text”. Finally, the process repeats for a third time, using “author_name” to find the names of the authors, as they are identified by the class of “author”.
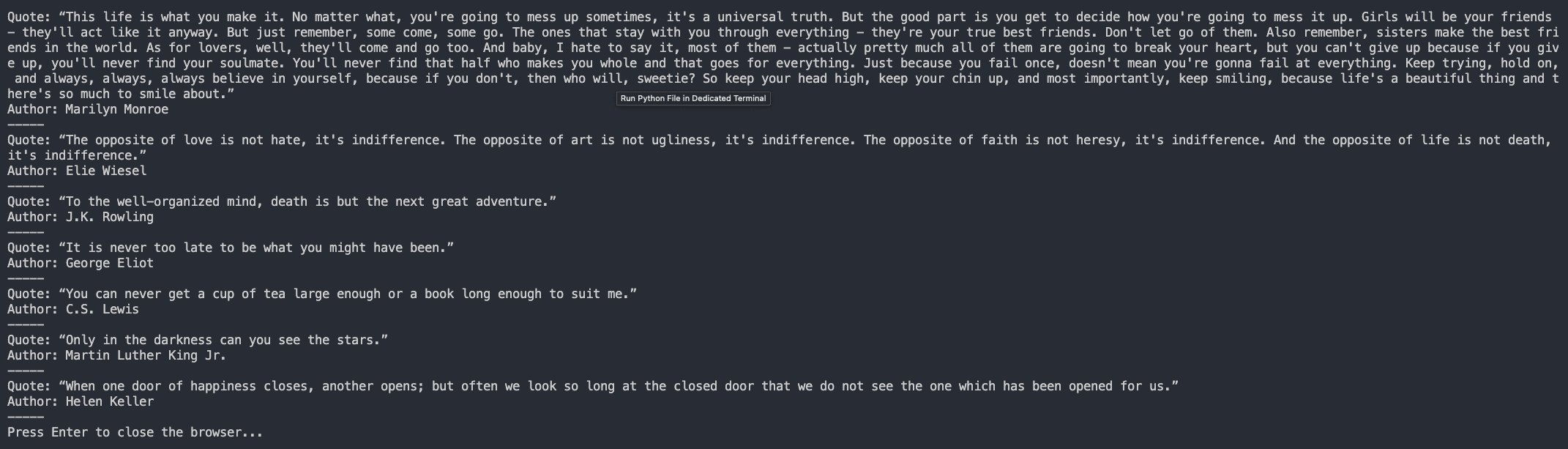
You’ve now successful used selenium and Python to scrape a website:
Common Blockers
When using tools like Selnium, its common you’ll come across blockers on page. If you’ve ever opened a website for the first time and been asked whether or not you consent to cookie collection- you might find that these popups cause roadblocks in your automations. In this example, we’ll use the Financial Times. Here’s an example of how we might deal with them.
Pop Ups
Pop ups can be frustrating for a user, and stop automations in their track. These can be slightly more complicated than just clicking a button. On the example site, the cookie popup itself sits inside another element called an “inline frame”. An inline frame is used to embed another document inside the current HTML. Clicking buttons is a fairly simple process, but you need to ensure you’re locating the content in the right place before attempting to click and close the popup:
<iframe src="https://consent-manager.ft.com/index.html?hasCsp=true&message_id=1161903&consentUUID=null&consent_origin=https%3A%2F%2Fconsent-manager.ft.com%2Fconsent%2Ftcfv2&preload_message=true&version=v1" id="sp_message_iframe_1161903" title="SP Consent Message"></iframe>
This is the source code for the consent pop up, where the “Accept Cookies” button will lie, waiting to be clicked and closed. Here, we can use a python loop to get inside the iframe, find the button, click it, and carry on:
try:
iframes = driver.find_elements(By.TAG_NAME, "iframe")
for iframe in iframes:
driver.switch_to.frame(iframe)
try:
button = WebDriverWait(driver, 5).until(
EC.element_to_be_clickable((By.XPATH, '//button[@title="Accept Cookies" and @aria-label="Accept Cookies"]'))
)
button.click()
break
except:
driver.switch_to.default_content()
Our code checks if a button is inside an iframe on the page. It first grabs all the iframes using find_elements and loops through each one. For each iframe, it switches the WebDriver focus to that iframe with switch_to.frame(), so it can interact with the elements inside. This way, the script can work with buttons and other elements that might be hidden inside iframes.
Once we’ve established where the button is, we can then move the script to click it. We’re using the “By.XPATH”. This is a more flexible approach, allowing us to chose which button we want to find by specific attributes or text.
EC.element_to_be_clickable((By.XPATH, '//button[@title="Accept Cookies" and @aria-label="Accept Cookies"]'))
Looking into the source code of the site, we’d already identified that the button had both a title and aria label; a label used to give more context on specific functions of that element. This makes it perfect to use when looking for the button as it tells us exactly what its for, so we’ll direct our script to look for these specifically. This can be particularly useful when you want to make sure you’re click the specific button.
Finally, we’ll break the loop and switch out of the iframe and back to the content, allowing us to move forward. Without this, you might find yourself stuck in the iframe we. Now, you can move on to the next part of your automation, successfully closing the popup (in this case, consenting to cookies).
Inputting Data
This can be applied to multiple use case, such as form filling or logging in. Following on from the previous example where we successful made it past any non-negotiable forms, there may be times where you’re looking to automate data input.
For our purpose, we’re signing into he same site (using test details) and have already navigated directly to the login page. We’re pre-defining the variables with our email address and password so that we can use Selenium to pull the string from these and input into the form:
password = "testing123" email_input = driver.find_element(By.ID, "enter-email") email_input.send_keys(email) button = driver.find_element(By.ID, "enter-email-next") button.click() password_input = driver.find_element(By.ID, "enter-password") password_input.send_keys(password) sign_in = driver.find_element(By.ID, "sign-in-button") button.click
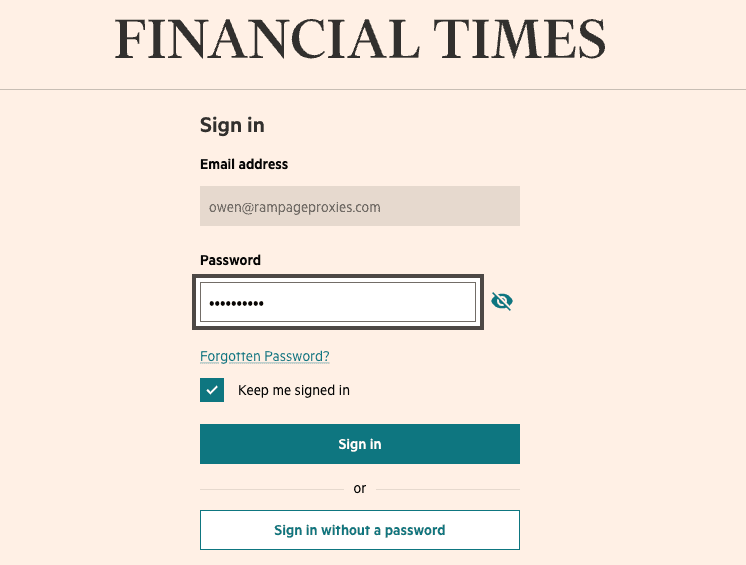
On this site, login is broken down into two components. You’ll need to enter your email address, click the button, and then input the password after. Using Selenium to identify the input fields by their ID’s of both “enter-email” and “enter-password”, with a button press in-between.
Once completed, the code above will automatically input the details you provided and navigate through the login process.
Best Practices
Web scraping is a powerful tool to be used across all industries. For example, it's popularly used in price comparison sites to make sure you get the best price. There are rules for scraping, a series of best practices you should follow. This ensures your scraping stays ethical and remains as lightweight as possible. Here’s some best practises for web scraping:
Use Proxies:
Proxies are an integral part of web scraping. You should consider using rotating proxies to allow for rotating IP addresses. This will significaltnly reduce the chance of your requests being detected, or blocked outright. Remember, if the website is focusing its resources on blocking your traffic, thats reducing the resources available elsewhere. Large amounts of traffic coming from a single IP address is likely to be detected as bot traffic and blocked, being lablled as “non human” activity.
The good new is, all our proxies available for purchase are suitable for web scraping. Take a look at the various providers to see what fits your budget best.
Respect Robots.txt:
This is a text file used by website administrators to dictate the terms of scrapers and crawlers. This will include the details such as what can and can’t be scraped, the frequency of when you can scrape, or what specific user agents are allowed to do so. This file is found in the root directory of the site, and should be checked regularly before any scraping is done. It’s important to note that some sites might request against scraping altogether.
Be In and Out:
Web scraping should be as gentle as possible on a website. Done well, a site should by no means know that it is being scraped. This means a priority of your scraping activity should be ensuring the scrapers efficiency. Send as few requests as required, being sure to abide by the times given in the robots.txt file and only extracting the necessary data. Add delays to your requests, look to scrape the site at off peak times (when server load is likely to be at the lowest) and look to utilise proxies.
Adding delays also prevents from too many requests being sent to quickly. Sending hundreds of requests with a second could cause a large resource spike, effectively DDOSing the site.
Build your own scraper:
Building your own customer web scraper may take longer, but this is another step towards only requesting what you need from the website. By building a customer web scraper, you can ensure that it is fit for the exact purpose, minimising the resources it requires when extracting the data. As we’ve seen in this guide, we’ve utilised a variety of libraries such as Selenium and BeautifulSoup to build a purpose built tool.
Conclusion
You’re ready and equipped with the knowledge and tools to begin your web scraping journey. In this guide, we’ve covered the basics of Selenium and used this in conjunction with Python to extract specific information from a website.
Frequently asked questions
Rampage allows purchase from 10 of the largest residential providers on one dashboard, starting at just 1GB. There's no need to commit to any large bandwidth packages. Through our dashboard, you're also given options such as static or rotating proxies and various targeting options, all for a single price per provider.
All purchases are made through the Rampage dashboard.
Rampage also offers high-quality, lightning-fast ISP and DC proxies available in the US, UK, and DE regions.
If you're unsure what provider would suit your use case base, please contact our support; we'll gladly assist.
Why Rampage is the best proxy platform
Unlimited Connections and IPs
Limitations are a thing of the past. Supercharge your data operations with the freedom to scale as you need.
Worldwide Support
From scraping multiple web targets simultaneously to managing multiple social media and eCommerce accounts – we’ve got you covered worldwide.
Speedy Customer Support
We offer 24/7 customer support via email and live chat. Our team is always on hand to help you with any issues you may have.
Digital Dashboard
Manage all of your proxy plans on one dashboard - no more logging into multiple dashboards to manage your proxies.